
Hi! I am currently a PhD student in the Department of Computer Science of Duke University, and a member of Computational Evolutionary Intelligence (CEI) Lab under the supervision of Prof. Hai “Helen” Li and Prof. Yiran Chen.
Before joining Duke University, I received my M.S. degree from Peking University (北京大学) in 2024, under the supervision of Prof. Hailong Jiao. I obtained my BEng degree from Southern University of Science and Technology (南方科技大学) in 2021, advised by Prof. Fengwei An. For now, my research realm focuses on algorithm-hardware co-design for efficient ML/AI. Please don’t hesitate to reach out if you have any questions or interests🍀.
Publications Overview: (Bold indicates first-author work)
- Computer Architecture & Integrated Circuit: HPCA’26, TCSVT’24, TCAS-II’24, ISCA’26, GLSVLSI’26, ISSCC’25, ICCAD’23, IOT-J’23, TCAS-I’21
- Efficient ML Algorithms: DAC’26, ICME’25, CVPR’26-Findings, ICLR’26, NeurIPS’26, NeurIPS’26
- Survey: CSUR’26, AAAI-SSS’25 (Best paper award)
E-mail: yuzhe.fu@duke.edu
🔥 News
- 2026.07: 🏆 Honored to receive the DAC Young Fellow Award!
- 2026.06: (CSUR’26) One paper has been accepted by CSUR 26! Cheers!
- 2026.03: (ISCA’26) EVA and OASIS have been accepted by ISCA 26! Congrats!
- 2026.02: (DAC’26) FlashFPS has been accepted by DAC 26! Codes.
- 2026.01: (ICLR’26) IncVGGT has been accepted by ICLR 26! Congrats!
- 2025.11: (HPCA’26) FractalCloud has been accepted by HPCA 26! Codes.
- 2025.09: (NeurIPS’26) Angles Don’t Lie
and KVCOMM
have been accepted by NeurIPS 26! Congrats!
- 2025.06: (PhD Journey) Finish my Reasearch Initial Project Defense ✅, which is the first milestone in my PhD journey!
- 2025.03: (ICME’25) “SpeechPrune” has been accepted by ICME 25 (Oral, Top 15%)! Dataset.
- 2025.02: (AAAI-SSS’25, Best Paper Award) “GenAI at the Edge” has been accepted by AAAI-SSS 25!
- 2024.10: (ISSCC’25) “Nebula” has been accepted by ISSCC 25!
- 2024.08: (PhD Journey) Starting my PhD journey — wish me luck🍀!
- 2024.04: (TCSVT’24) “SoftAct” has been accepted by IEEE TCSVT (JCR-Q1)!
- 2024.02: (TCAS-II’24) “Multi-Stream FPS accelerator” has been accepted by IEEE TCAS-II (JCR-Q1)!
- 2023.08: (IOTJ’23) “Sagitta” has been accepted by IEEE IOTJ (JCR-Q1)!
- 2023.07: (ICCAD’23) “PNN Accelerator” has been accepted by ICCAD 23!
- 2021: (TCAS-I’21) “Stereo-depth processor” has been accepted by TCAS-I (JCR-Q1)!
- Bold: Main paper. Others: Collaborative papers.



💻 Internships
- 2026.05 - 2026.08, Research Intern, Siemens, USA.
📝 Selected Publications
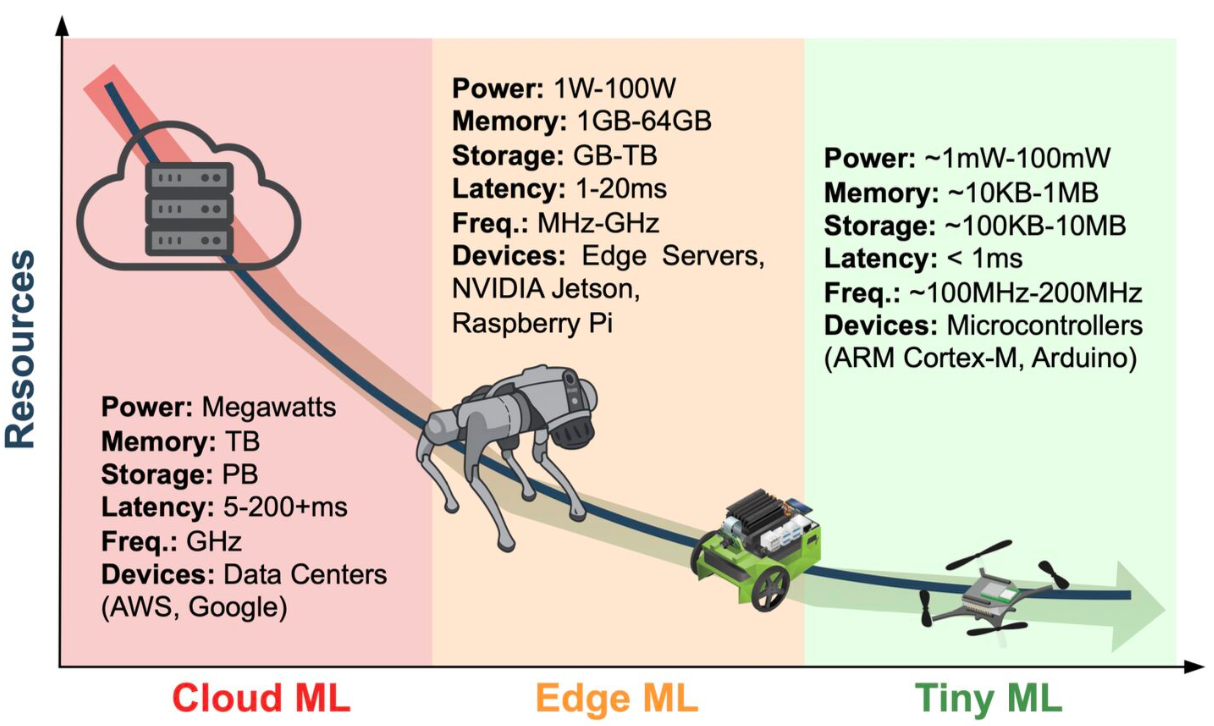
Generative AI at the Edge: A Comprehensive Survey of Architectures, Hardware and Applications
Mozhgan Navardi#, Yuzhe Fu#, Yueqian Lin#, Hai “Helen” Li, Yiran Chen, Tinoosh Mohsenin.
2026, ACM Computing Surveys (CSUR’26)
[pdf]
Abstract
Generative Artificial Intelligence (GenAI) leverages generative models, including Diffusion models and Foundation Models (FMs) such as Large Language Models (LLMs), to generate new data. GenAI has attracted growing attention as it enables applications such as text generation, image synthesis, and multimodal reasoning. However, deploying such GenAI models on resource-constrained edge devices poses key challenges. Edge devices typically have limited computational power and strict energy budgets. They also face the memory-wall problem, where the cost of moving data between memory and compute units exceeds the cost of computation itself. This survey provides a comprehensive overview of techniques that enable GenAI deployment at the edge, covering software optimizations, hardware innovations, and system-level frameworks. While all three categories are discussed, particular emphasis is given to hardware-focused approaches. We review recent hardware studies and classify them into three main levels: computation, memory, and scheduling, with eight finer-grained subcategories that capture the mainstream hardware techniques. Many of these are hardware–software co-design strategies that align GenAI workloads with edge resource constraints. By synthesizing state-of-the-art solutions and identifying open challenges, this survey outlines a roadmap for building efficient GenAI systems at the edge.
FlashFPS: Efficient Farthest Point Sampling for Large-Scale Point Clouds via Pruning and Caching
Yuzhe Fu, H. Ye, C. Guo, J. Zhang, Q. Wang, Y. Lin, C. Zhou, Hai “Helen” Li, Yiran Chen.
2026, IEEE/ACM Design Automation Conference (DAC’26) (Accepted)
Acceptance Rate: 22.3%
Abstract
Point-based Neural Networks (PNNs) have become a key approach for point cloud processing. However, a core operation in these models, Farthest Point Sampling (FPS), often introduces significant inference latency, especially for large-scale processing. Despite existing CUDA- and hardware-level optimizations, FPS remains a major bottleneck due to exhaustive computations across multiple network layers in PNNs, which hinders scalability.Through systematic analysis, we identify three substantial redundancies in FPS, including unnecessary full-cloud computations, redundant late-stage iterations, and predictable inter-layer outputs that make later FPS computations avoidable. To address these, we propose FlashFPS, a hardware-agnostic, plug-and-play framework for FPS acceleration, composed of FPS-Prune and FPS-Cache. FPS-Prune introduces candidate pruning and iteration pruning to reduce redundant computations in FPS while preserving sampling quality, and FPS-Cache eliminates layer-wise redundancy via cache-and-reuse. Integrated into existing CUDA libraries and state-of-the-art PNN accelerators, FlashFPS achieves 5.16× speedup over the standard CUDA baseline on GPU and 2.69× on PNN accelerators, with negligible accuracy loss, enabling efficient and scalable PNN inference.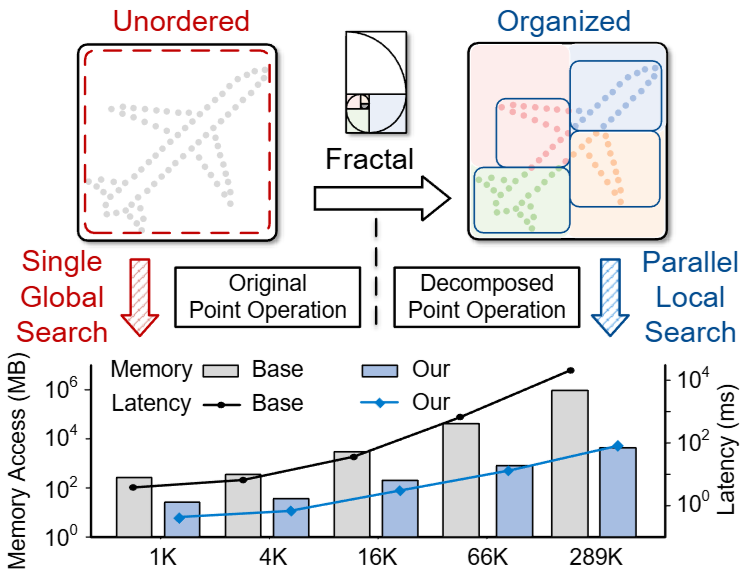
FractalCloud: A Fractal-Inspired Architecture for Efficient Large-Scale Point Cloud Processing
Yuzhe Fu, C. Zhou, H. Ye, B. Duan, Q. Huang, C. Wei, C. Guo, Hai “Helen” Li, Yiran Chen.
2026, IEEE International Symposium on High-Performance Computer Architecture (HPCA’26)
Acceptance Rate: 19.8%
Abstract
Three-dimensional (3D) point clouds are increasingly used in applications such as autonomous driving, robotics, and virtual reality (VR). Point-based neural networks (PNNs) have demonstrated strong performance in point cloud analysis, originally targeting small-scale inputs. However, as PNNs evolve to process large-scale point clouds with hundreds of thousands of points, all-to-all computation and global memory access in point cloud processing introduce substantial overhead, causing O(n2) computational complexity and memory traffic where n is the number of points. Existing accelerators, primarily optimized for small-scale workloads, overlook this challenge and scale poorly due to inefficient partitioning and non-parallel architectures. To address these issues, we propose FractalCloud, a fractal-inspired hardware architecture for efficient large-scale 3D point cloud processing. FractalCloud introduces two key optimizations: (1) a co-designed Fractal method for shape-aware and hardware-friendly partitioning, and (2) block-parallel point operations that decompose and parallelize all point operations. A dedicated hardware design with on-chip fractal and flexible parallelism further enables fully parallel processing within limited memory resources. Implemented in 28 nm technology as a chip layout with a core area of 1.5 mm2, FractalCloud achieves 21.7× speedup and 27× energy reduction over state-of-the-art accelerators while maintaining network accuracy, demonstrating its scalability and efficiency for PNN inference.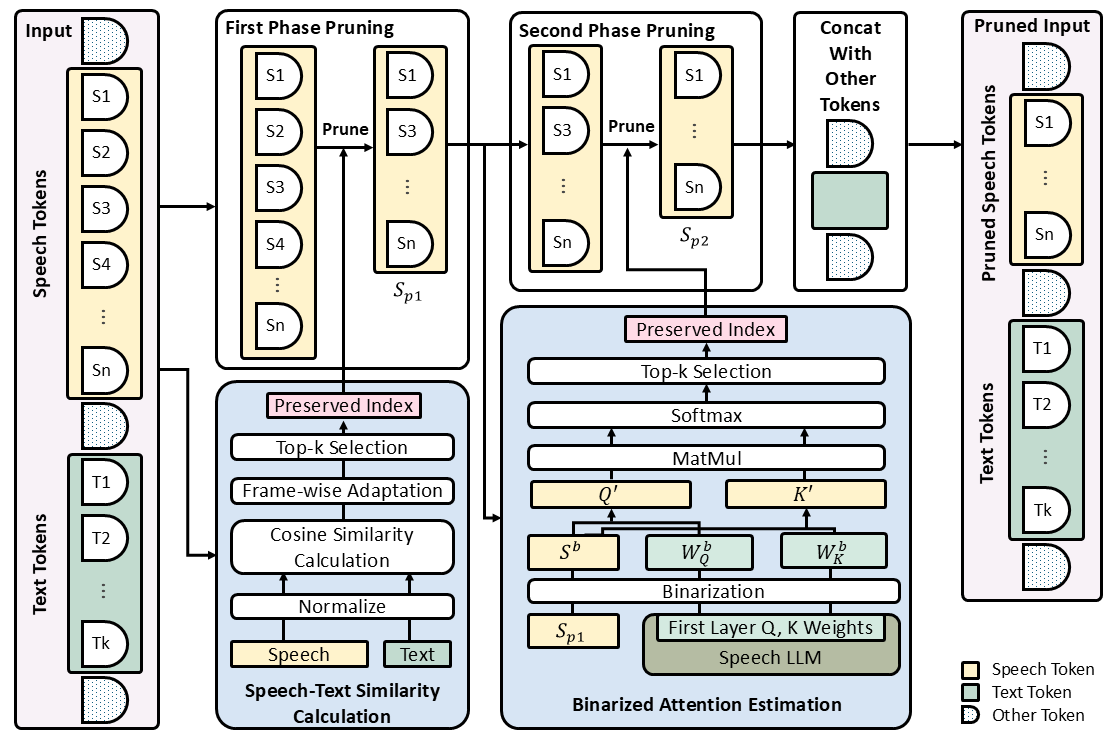
SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval
Yueqian Lin#, Yuzhe Fu#, J. Zhang, Y. Liu, J. Zhang, J. Sun, Hai “Helen” Li, Yiran Chen.
2025, IEEE International Conference on Multimedia & Expo (ICME’25) (# with equal contribution)
Oral, Top 15% in all submissions
Abstract
While current Speech Large Language Models (Speech LLMs) excel at short-form tasks, they struggle with the computational and representational demands of longer audio clips. To advance the model's capabilities with long-form speech, we introduce Speech Information Retrieval (SIR), a long-context task for Speech LLMs, and present SPIRAL, a 1,012-sample benchmark testing models’ ability to extract critical details from long spoken inputs. To overcome the challenges of processing long speech sequences, we propose SpeechPrune, a training-free token pruning strategy that uses speech-text similarity and approximated attention scores to efficiently discard irrelevant tokens. In SPIRAL, SpeechPrune achieves accuracy improvements of 29% and up to 47% over the original model and the random pruning model at a pruning rate of 20%, respectively. SpeechPrune can maintain network performance even at a pruning level of 80%. This highlights the potential of token-level pruning for efficient and scalable long-form speech understanding.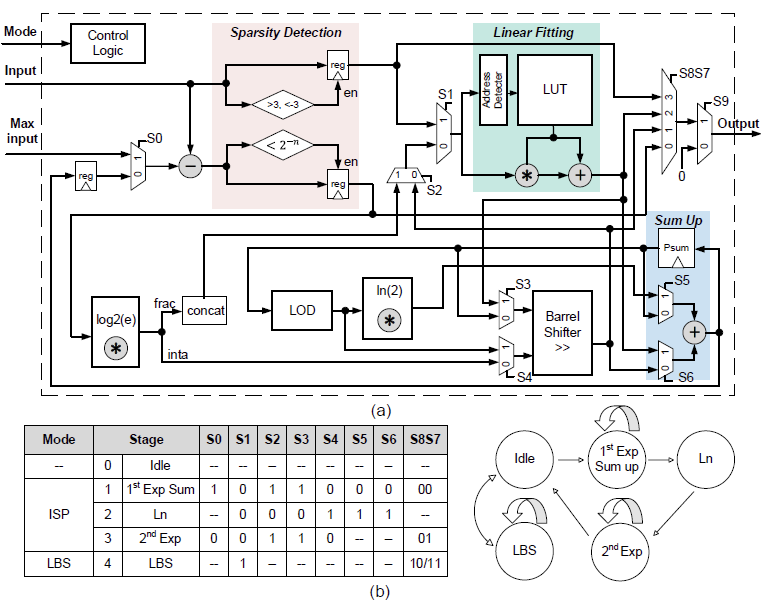
SoftAct: A High-Precision Softmax Architecture for Transformers Supporting Nonlinear Functions
Yuzhe Fu, C. Zhou, T. Huang, E. Han, Y. He, Hailong Jiao.
2024, IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
[pdf]
Abstract
Transformer-based deep learning networks are revolutionizing our society. The convolution and attention co-designed (CAC) Transformers have demonstrated superior performance compared to the conventional Transformer-based networks. However, CAC Transformer networks contain various nonlinear functions, such as softmax and complex activation functions, which require high precision hardware design yet typically with significant cost in area and power consumption. To address these challenges, SoftAct, a compact and high-precision algorithm-hardware co-designed architecture, is proposed to implement both softmax and nonlinear activation functions in CAC Transformer accelerators. An improved softmax algorithm with penalties is proposed to maintain precision in hardware. A stage-wise full zero detection method is developed to skip redundant computation in softmax. A compact and reconfigurable architecture with a symmetrically designed linear fitting module is proposed to achieve nonlinear functions. The SoftAct architecture is designed in an industrial 28-nm CMOS technology with the MobileViT-xxs network as the benchmark. Compared with the state of the art, SoftAct improves up to 5.87% network accuracy, 153.2× area efficiency, and 1435× overall efficiency.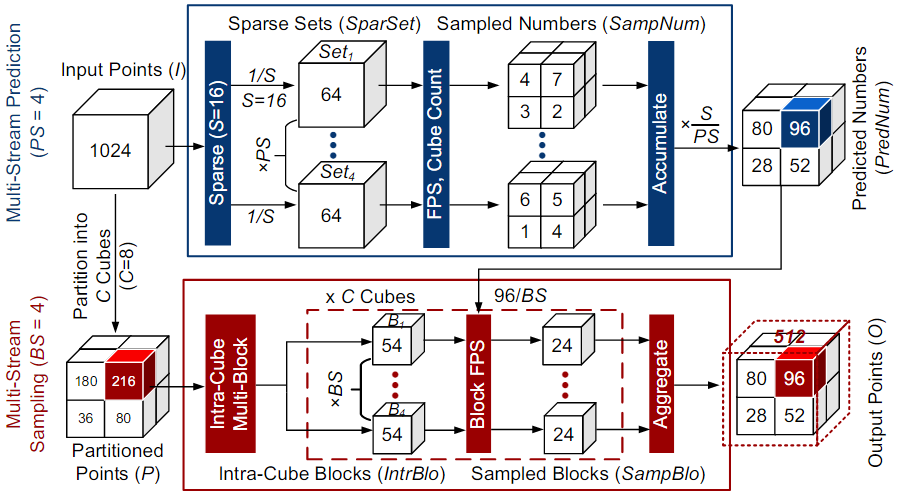
Adjustable Multi-Stream Block-Wise Farthest Point Sampling Acceleration in Point Cloud Analysis
Changchun Zhou#, Yuzhe Fu#, Y. Ma, E. Han, Y. He, Hailong Jiao.
2024, IEEE Transactions on Circuits and Systems II: Express Briefs (TCAS-II) (# with equal contribution)
[pdf]
Abstract
Point cloud is increasingly used in a variety of applications. Farthest Point Sampling (FPS) is typically employed for down-sampling to reduce the size of point cloud and enhance the representational capability by preserving contour points in point cloud analysis. However, due to low parallelism and high computational complexity, high energy consumption and long latency are caused, which becomes a bottleneck of hardware acceleration. In this brief, we propose an adjustable multi-stream block-wise FPS algorithm, adjusted by four configurable parameters, according to hardware and accuracy requirements. A unified hardware architecture with one parameter is designed to implement the adjustable multi-stream block-wise FPS algorithm. Furthermore, we present a rapid searching algorithm to select the optimal configuration of the five parameters. Designed in an industrial 28-nm CMOS technology, the proposed hardware architecture achieves a latency of 0.005 (1.401) ms and a frame energy consumption of 0.09 (27.265) µJ/frame for 1 k (24 k) input points at 200 MHz and 0.9 V supply voltage. Compared to the state of the art, the proposed hardware architecture reduces the latency by up to 99.9%, saves the energy consumption by up to 99.5%, and improves the network accuracy by up to 9.34%.📝 Collaborative Publications
ISCA’26 EVA: Accelerating LLM Decoding via an Efficient Vector Quantization Architecture. Bowen Duan, C. Guo, C. Wei, H. Shan, Yuzhe Fu, X. Chen, Y. Xu, Z. Zhang, C. Zhou, Hai Li, Yiran Chen. 2026, International Symposium on Computer Architecture (ISCA) [pdf], [Codes]

ISCA’26 OASIS: Outlier-Aware LUT-Based GEMM with Dual-Side Quantization for LLM Inference Acceleration. Xueying Wu, B. Zhou, Z. Gao, Yuzhe Fu, Q. Zheng, Y. He, Hai Li. 2026, International Symposium on Computer Architecture (ISCA) [pdf]
GLSVLSI’26 Frame Skipping Architecture for Video-Language Model Acceleration. Haoxuan Shan, C. Wei, C. Guo, Yuzhe Fu, T. Liang, Hai Li, Yiran Chen. 2026, IEEE/ACM Great Lakes Symposium on VLSI (GLSVLSI) [pdf]
ICLR’26 IncVGGT: Incremental VGGT for Memory-Bounded Long-Range 3D Reconstruction. Keyu Fang, C. Zhou, Yuzhe Fu, Hai Helen Li, Yiran Chen. 2026, International Conference on Learning Representations (ICLR) [pdf]
NeurIPS’26 Angles Don’t Lie: Unlocking Training-Efficient RL Through the Model’s Own Signals. Qinsi Wang, J. Ke, H. Ye, Y. Liu, Yuzhe Fu, J. Zhang, K. Keutzer, C. Xu, and Yiran Chen. 2026, Conference on Neural Information Processing Systems (NeurIPS) [pdf], [Codes]
NeurIPS’26 KVCOMM: Online Cross-context KV-cache Communication for Efficient LLM-based Multi-agent Systems. Hancheng Ye, Z. Gao, M. Ma, Q. Wang, Yuzhe Fu, M. Chung, Y. Lin, Z. Liu, J. Zhang, D. Zhuo, and Yiran Chen. 2026, Conference on Neural Information Processing Systems (NeurIPS) [pdf], [Codes]
CVPR’26-Findings Hippomm: Hippocampal-inspired multimodal memory for long audiovisual event understanding. Yueqian Lin, Q. Wang, H. Ye, Yuzhe Fu, Hai Li, and Yiran Chen. 2026, CVPR, Findings Track [pdf], [Codes]

ISSCC’25 Nebula: A 28-nm 109.8 TOPS/W 3D PNN Accelerator Featuring Adaptive Partition, Multi-Skipping, and Block-Wise Aggregation. Changchun Zhou, T. Huang, Y. Ma, Yuzhe Fu, S. Qiu, X. Song, J. Sun, M. Liu, Y. Yang, G. Li, Y. He, Hailong Jiao. 2025, International Solid-State Circuits Conference (ISSCC) [pdf]
AAAI-SSS’25 (Best Paper Award) GenAI at the Edge: Comprehensive Survey on Empowering Edge Devices. M. Navardi, R. Aalishah, Yuzhe Fu, Y. Lin, Hai Li, Yiran Chen and Tinoosh Mohsenin. 2025, AAAI Spring Symposium Series (AAAI SSS) [pdf]
ICCAD’23 An Energy-Efficient 3D Point Cloud Neural Network Accelerator with Efficient Filter Pruning, MLP Fusion, and Dual-Stream Sampling. C. Zhou, Yuzhe Fu, M. Liu, S. Qiu, G. Li, Y, He, Hailong Jiao. 2023, IEEE/ACM International Conference On Computer Aided Design [pdf], [YouTube]
IoTJ’23 Sagitta: An Energy-Efficient Sparse 3D-CNN Accelerator for Real-Time 3D Understanding. C. Zhou, M. Liu, S. Qiu, X. Cao, Yuzhe Fu, Y. He, Hailong Jiao. 2023, IEEE Internet of Things Journal [pdf]
TCAS-I’21 A 4.29 nJ/pixel stereo depth coprocessor with pixel level pipeline and region optimized semi-global matching for IoT application. P. Dong, Z. Chen, Z. Li, Yuzhe Fu, L. Chen, Fengwei An. 2021, IEEE Transactions on Circuits and Systems I: Regular Papers [pdf]
📃 Patent
- A high-precision approximate calculation device for softmax function, 2024, CN Patent, CN118733946B.
- Low-power-consumption stereo matching system and method for acquiring depth information, 2020, CN Patent, CN112070821A / WO2022021912A1
💻 Academic Service
- Conference: HPCA-AE’26, AAAI’26, ICME’26,’25, AICAS’25,’23, AVSS’25.
- Journal: TCSVT’24, ELL’25,’24.
- Help to review: ASPLOS’26, ISCA’26,’25, MICRO’26,’25, HPCA’26, DAC’26.
💬 Teaching Assistant
- CS372 Introduction to Applied Machine Learning (25 Fall)
🍀 Tape Out
- An energy-efficient pipelined and configurable 3D point cloud-based neural network accelerator is being designed in TSMC 28-nm HPC technology with an area of 2.0 mm×1.5 mm and is taped out in July 2023.
- A 4.5 TOPS/W sparse 3D-CNN accelerator for real-time 3D understanding was fabricated in UMC 55-nm low-power CMOS technology with an area of 4.2 mm×3.6 mm in August 2020.
🎖 Honors and Awards
- 2026 DAC Young Fellow.
- 2025 Best Paper Award (2nd Place) in AAAI Spring Symposium Series.
- 2021 Excellent Graduate Award, Southern University of Science and Technology
- 2021 Best Presentation Award in IEEE CASS Shanghai and Shenzhen Joint Workshop
- 2020 National Scholarship, Ministry of Education of the PRC (The highest scholarship for Chinese undergraduates)
 About Me:
About Me:
- I am a easy-going and spirited individual with a passion for life. My enthusiasm not only drives my own life but also positively influences those around me.
- Interests and Hobbies: fitness, jogging, swimming, photography, traveling. (Here is a short 📸 video about my graduation trip in 2021.)